
Non c’è parola forse più abusata di Business continuity; anzi, forse una c’è, ed è sicuramente blockchain. Nel dilagare di inglesismi che spesso finiscono per sembrare più supercazzole che altro, la continuità del business in questi termini si traduce, quasi automaticamente, in una adeguata politica di disaster recovery. Il recupero da disastri imprevedibili e naturali, come potrebbero essere ad esempio incendi, blackout che danneggiano gli hard disk, addirittura errori umani. In molti casi la costante è sempre la stessa: non era stato fatto un backup di recente, ed i dati hanno finito per essere persi per sempre. Questo rende il disaster recovery meno banale di quello che potrebbe sembrare a prima vista, e meritevole di un minimo di dissertazione ed approfondimento.
Attacchi informatici, disastri naturali, malware, ransomware di ogni tipo minacciano ogni giorno l’integrità dei nostri dati: il più delle volte la minaccia è subdola, quasi sottintesa, raramente esplicitata e il più delle volte sottovalutata dai vertici aziendali. Non è un caso che, di fatto, sia una situazione abbastanza tipica piangere sul latte versato quando ormai non c’è molto da fare, e la tragedia tecnologica in atto è ormai irreversibile.
Tipologie di disaster recovery
Le policy di recupero possono variare di azienda in azienda, e possedere dei tratti più o meno specialistici a seconda delle circostanze; non esiste una soluzione valida universalmente e tutto, come spesso accade nell’informatica, può essere considerato opinabile e gestibile al meglio (… sempre nella speranza che ciò sia un’opportunità di miglioramento costante, non un limite!). In genere le aziende sfruttano delle classiche politiche di backup temporizzate, quindi automatizzate, in grado di salvare i dati su una sede apposita per limitare i danni nel caso in cui i dati originali diventassero irragiungibili per motivi di forza maggiore (un allagamento al data center, un incendio, un blackout che ha rovinato gli hard disk, un corto circuito ecc.). Questo backup funziona per salvare i dati sfruttando eventuali meccanismi di ridondanza, ovvero di copie di backup replicate su più supporti per evitare che il restore fallisca da una singola copia senza dare altre possibilità.
Nell’ottica cloud as-a-service, alcune aziende possono offrire soluzioni cosiddette Disaster Recovery as-a-Service (cosiddetti DRaaS), che permette di effettuare il ripristino all’occorrenza interfacciandosi con l’esterno in modo sicuro e sincronizzati quasi in tempo reale, il più delle volte. In altri casi, si ricorre alla virtualizzazione per effettaure delle copie sincronizzate dei dati e delle applicazioni che girano per far funzionare il core business aziendale.
Alcune aziende affiancano i backup, ad esempio, ad un cold site, cioè ad un’infrastruttura identica all’originale ma non sincronizzata in tempo reale, in modo che in caso di disastri si possa switchare dall’originale alla copia in modo “indolore” (per modo di dire, s’intende). Questa logica è spesso implicita e diventa una soluzione di emergenza, l’unica attuabile quando il disastro è irreversibile. Per venire incontro a questo genere di esigenze, si sfrutta spesso la logica della logica cosiddetta di hot site, che funziona come il cold site ma presenta in più una sincronizzazione dei dati frequente, quasi in tempo reale (ed ovviamente ha dei costi aziendali che non tutti possono permettersi).
Non sempre, inoltre, il recupero è immediato e non sempre è disponibile per i dati modificati più di recente, che in caso di disastri imprevedibili vengono quasi sempre persi per sempre.
Esempio di disaster recovery per un sito web
Di fatto, il disaster recovery si pone in una posizione esterna rispetto all’infrastruttura, curando la possibilità di effettuare periodicamente dei backup di ogni genere di dato. Nel caso dei server VPS di Digital Ocean, ad esempio, per prevenire disastri irreversibili si possono abilitare dei backup automatici ogni settimana: è un caso molto semplice, ma immediatamente comprensibile, in cui sostanzialmente non ci si limita ad un backup del database o dei file ma dell’intera droplet, cioè si realizza una copia completa del sistema (database, file, email ecc.) che fa funzionare il sito. È altresì fondamentale che il backup sia mantenuto su un ambiente separato, e non nella droplet stessa, perchè ovviamente se perdessimo il controllo al sistema per via di un crash (nel cosiddetto caso peggiore, diciamo) non avremmo modo di andare nemmeno a prenderci il backup.
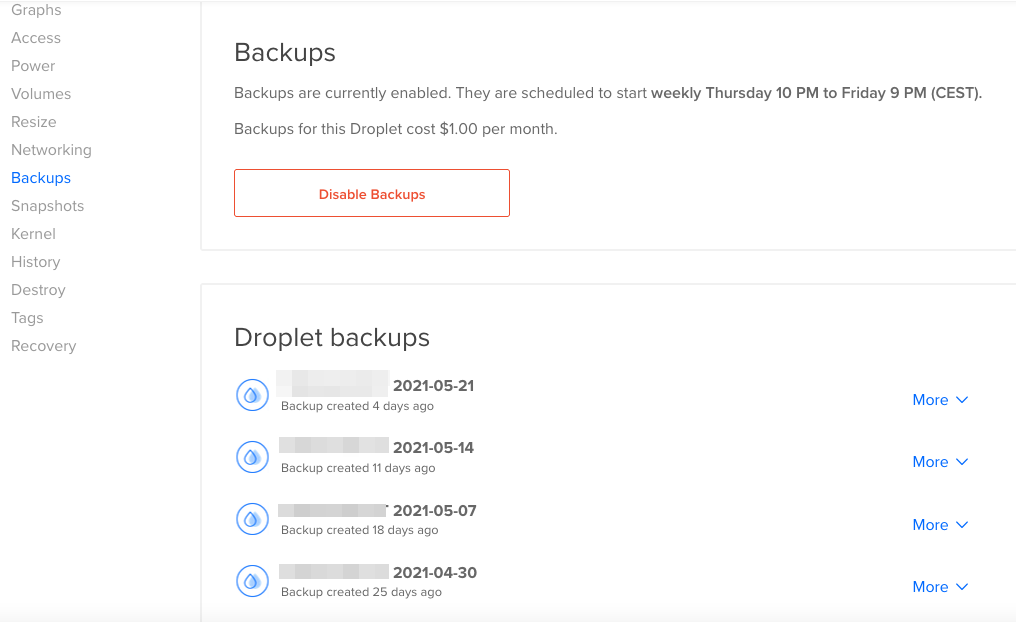
Di fatto, la politica di disaster recovery è in questo caso semplice, funzionale e lineare: se il sito in una droplet dovesse crashare, basterà ripristinare l’ultimo backup con un semplice click.

Poiché gli attacchi informatici e le calamità naturali sono sempre più diffusi, la pianificazione del Disaster Recovery diventa più che mai essenziale per garantire la Business Continuity. La valutazione del rischio e un’analisi dell’impatto aziendale che quantifichi i possibili effetti di un evento disastroso sono strumenti efficaci per ottenere assistenza nella gestione di un piano di Disaster Recovery.
Backup automatici con Updraft
Nell’ambito della gestione dei siti web in WordPress, un modo simile per prevenire disastri “in piccolo” e garantire business continuity di qualsiasi sito, è molto comune fare uso di una soluzione di backup che abbia l’accortezza, per quanto abbiamo visto, di fare il backup in cloud e non in locale. Sono molte le soluzioni che fanno backup di file e database di un sito, ma se lo fanno in locale nella cartella del sito stesso non saranno mai funzionali al 100%.
Di fatto, è molto meglio andare ad effettuarli su un dispositivo in cloud, e senza scomodare cose troppo complicate: basta un semplice account Google Drive,e si salveranno i backup direttamente in quella cartella, in remoto, staccata dal sito ed accessibile da Gmail in caso di necessità in forma di file zip.

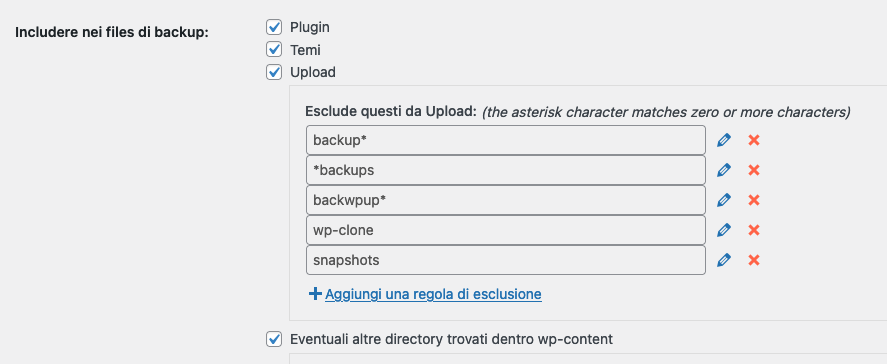
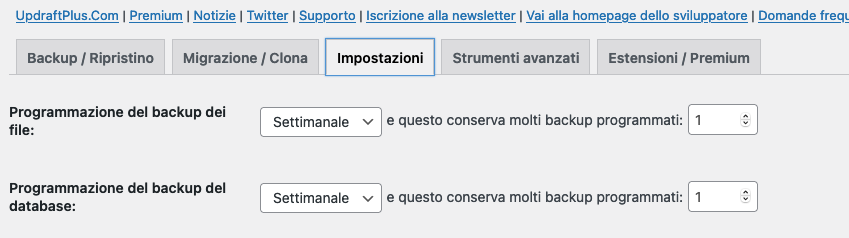
Updraft può essere installato da questo link, e già con la versione gratuita avrete un backup aggiornato del vostro sito realizzato in modo periodico (ogni ora, ogni due ore, una o due volte al giorno, ogni settimana oppure ogni 15 giorni) ed automatico.
Come funzionano le politiche di disaster recovery di un sito?
Sono numerosi gli elementi per la business continuity (che qui abbiamo riferito ad un sito web per semplicità, ma che potrebbe estendersi a molti altri tipi di dati o di app aziendali): in genere sono elementi discrezionali che deve essere il consulente IT o il manager a decidere e rendere prioritari.
Prima di tutto è molto importante documentare il processo, in modo tale che la procedura sia attuabile da più di un dipendente e si possa effettuare anche in modo non supervisionato (ovviamente, se possibile). La trasparenza e la chiarezza sono indispensabili in questo caso, unita alla scelta di adeguati punti di ripristino (Point Of Restore) oltre ad una frequenza di backup automatici adeguata ai ritmi di lavoro. Per intenderci: è poco funzionare avere un backup settimanale se i giorni di operatività sono 5 a settimana (rischiamo di rimanere troppo indietro), così come un backup giornaliero può rivelarsi poco adeguato in alcuni casi, mentre un backup orario potrebbe creare problemi di incongruenze ed operatività. La definizione delle corrette metriche di disaster recovery sono alla base della sicurezza e dell’efficacia della business continuity.
Foto di Hermann Traub da Pixabay